Uma coisa que me frustra muito é gente bem-intencionada que resolve fazer mais do que o combinado, pra ~surpreender.
Se havia algo combinado, ir além do combinado também é descumprir – especialmente quando a entrega precisa encaixar com as entregas dos outros.
Fazer isso de surpresa, e só revelar na hora de entregar, remove a oportunidade das outras partes adaptarem a tempo as entregas delas, que ficam desconexas ou até incompatíveis.
Quantos insucessos nascem dessa boa intenção? Já vi muitos, e todos me fizeram lamentar intensamente.
Não há pré-requisitos para se alinhar a causas meritórias – embora possa haver para ser aceito por grupos que se identificam com elas.
Idade não é mérito nem atesta sabedoria, mas minhas décadas me trouxeram uma experiência sólida em receber (e lidar com) gatekeeping, que é aquela atitude de quem se acha porteiro de boate do seu hobby, da sua causa, do fandon da sua banda preferida etc. e quer fazer a triagem de quem pode ou não se alinhar às mesmas preferências.
Sem tempo, irmão.
E essa experiência vem também porque eu meio que venci todas as loterias de entrar em campos que tem fãs intensos: código aberto/software livre, vôlei feminino, gostar ao mesmo tempo de punk rock, de heavy metal e de música eletrônica (e de avril lavigne), e mais.
Você pode imaginar quantas vezes eu ouvi invalidações das minhas preferências, ou aquela velha ladainha de "pra você apoiar esse _____ aqui que eu também apoio, primeiro precisa passar por esse meu critério de pureza".
Aliás: ouvi, ouço e certamente continuarei ouvindo, porque continuo apoiando essas mesmas causas e tendo as mesmas preferências.
Quando vai além do clubismo
Quando se trata de mero clubismo (e não inclui componentes de discriminação, em especial misoginia), esse tipo de coisa pode até ser folclórica, cultural, ainda que rasteira, contraproducente e merecendo ser superada logo.
Mas quando o gatekeeping quer restringir quem pode praticar atos de defesa a uma causa, e essa causa é meritória e positiva, ele se torna um obstáculo importante ao crescimento da causa, tristemente praticado por pessoas que acreditam estar defendendo algum ideal subjacente a essa causa.
Faz sentido preferir restringir quem age em apoio à mesma causa do que você? Em termos de escala de prioridades, não muito.
Atuando desde 1996 no mundo do código aberto, já recebi esse tipo de pressão muitas vezes, tanto da turma que se identifica com esse mesmo nome, quanto na que se alinha à Free Software Foundation (não é meu caso, há anos), e que muitas vezes quis me dizer que antes de eu defender alguma posição nesse âmbito, eu precisava completar os Doze Trabalhos de Hércules que eles haviam selecionado pra mim, ou ter me purificado em relação a algum pecado1.
Não é privilégio desses grupos, claro: assim como lá, em vários outros grupos (seja das artes, das causas sociais etc.) a gente percebe que no meio de uma maioria de gente legal, gentil e inclusiva, tem um percentual de pessoas barulhentas e abrasivas, que valorizam mais as diferenças do que as identidades, e exigem tributos e comprovações de fidelidade antes de expressar aceitação do apoio de quem não reza exatamente pela mesma cartilha ou venera os mesmos ídolos.
Uma solução eficaz pra mim, mas nem sempre feliz
Felizmente, a verdade é que não há pré-requisitos para se alinhar a causas meritórias, embora possa haver para ser aceito por indivíduos ou grupos que se identificam com elas.
Menos felizmente, ou talvez até infelizmente, eu acabei aprendendo a preferir defender os meus pontos de vista a partir de ações individuais, e não como parte de grupos – e uma das principais razões é que o gatekeeping alheio é uma força mais persistente do que a minha paciência para buscar inclusão e pertencimento.
Às vezes eu inspiro outras pessoas a aderirem ao mesmo esforço que eu, outras vezes não, mas por mim tudo bem: não estou fazendo pra ser aceito, e sim por acreditar em algo e em poder dar uma contribuição.
Grande Quintana sempre com a palavra certa.
Isso é uma coisa que me desmotivava, mas com a maturidade acabou se transformando em um impulso a mais, porque na real há um determinado percentual de pessoas que jamais irão nos aprovar, e eu realmente penso diferente delas, então podem me barrar do convívio delas quanto quiserem.
Certo estava Quintana: eles passarão, eu passarinho.
Pecado real ou imaginário – mas frequentemente real mesmo, porque eu já pequei bastante na vida. ↩
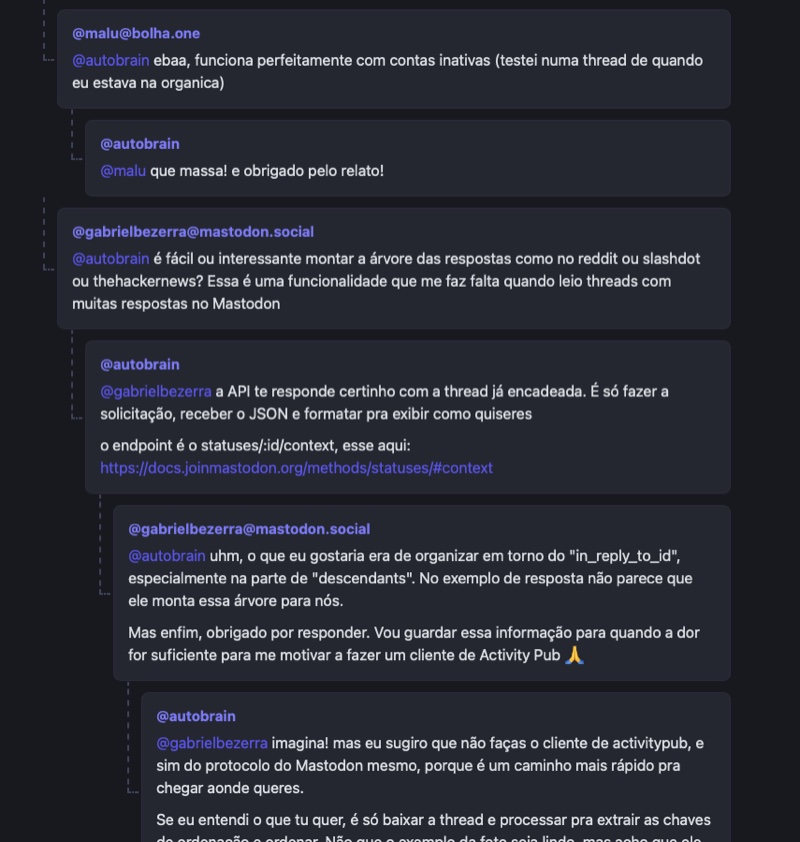
Criei um script shell (usando jq e curl) que recebe como parâmetro a URL de um post do Mastodon, e gera (em HTML ou no terminal) uma árvore encadeada das respostas a ele, como neste exemplo:
Uma árvore encadeada de respostas a um post no Mastodon
Na imagem acima você pode perceber que os posts estão encadeados de uma forma que indica visualmente, e em vários níveis, qual deles é resposta a qual outro.
Era madrugada e eu não percebi que a pergunta dele (desculpa, Gabriel!) veio no contexto da thread sobre o lançamento do meu app Estica, e assim na verdade era uma consulta sobre a possibilidade de eu agregar a ele esse recurso.
Entendi que era uma pergunta sobre viabilidade, e respondi explicando como ele podia implementar, e até dei um exemplo de código. A discussão foi boa, mas encerrou ali, sem a solução que o Gabriel queria.
O script
Como eu havia respondido ao Gabriel, a complexidade de implementar essa exibição não é das mais elevadas - a API do Mastodon oferece os dados necessários, e o esforço maior é na criação de um layout visual (do qual só fiz o mínimo necessário) do que em ter os dados da thread para trabalhar.
Para demonstrar isso, desenvolvi este script aqui, que funciona como prova de conceito: ele recebe como parâmetro a URL do post que inicia uma thread, e formata essa thread visualmente como uma árvore, tanto em texto puro (para o terminal) quanto em HTML (para a web).
Faça o download do script, renomeie para mastotree.sh, leia o código para compreendê-lo, dê permissão de execução, e aí o rode assim:
Você irá notar que o script não é dos mais curtos, mas a parte que interage com a API do Mastodon se concentra em meia dúzia de linhas - todo o restante são detalhes de ordenação e exibição dos dados recebidos.
Por isso, hoje me permiti ser menos didático e ir direto à aplicação. Interação com a API é a parte em que eu tenho mais lugar de fala, e front-end pra mim é sempre um oceano misterioso. No post Programando bots para o Mastodon: obtendo dados via API e em vários outros posts da tag Mastodon aqui do blog eu já mostrei detalhadamente como obter e tratar dados da API.
Mas o script, em sua forma atual, se limita ao essencial (por exemplo, incluí uma restrição fixa de só ir até ao 4º nível de respostas, e mostro só os campos mínimos necessários para fazer sentido, além de formatar insuficientemente o texto no terminal).
Ele é uma prova de conceito, e você pode reimplementá-lo em outras arquiteturas, e incluir funcionalidades adicionais. Afinal, é open source!
Está no ar o Estica, ferramenta de expansão (unroll) de threads do Mastodon e Fediverso, com recursos de formatação visual e exportação em Markdown.
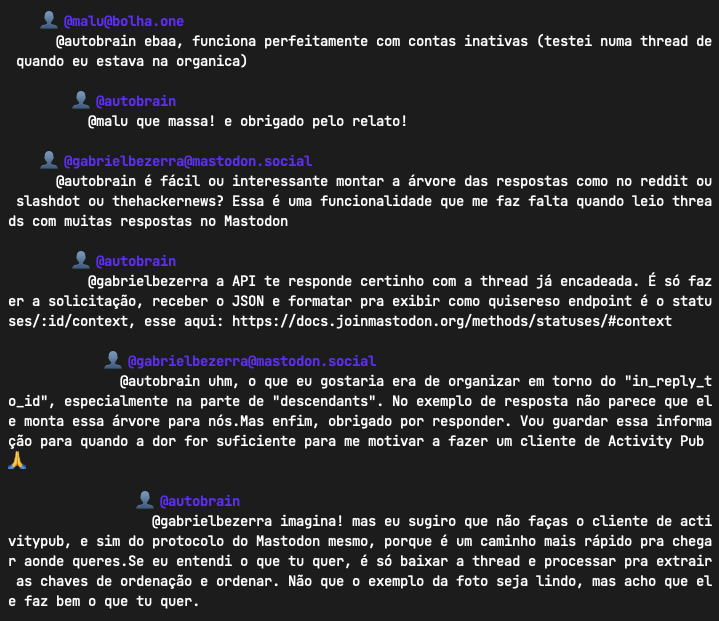
O funcionamento é simples: você preenche a URL de um post do Fediverso, e o Estica vai carregar esse post e suas respostas visíveis, exibindo-as na forma de uma thread bem formatada, com a íntegra dos posts, imagens e cards de anexos, prontinho pra gerar um documento em PDF ou copiar em Markdown para o Obsidian ou outro software em que você faça o seu arquivamento.
Tela do Estica, mostrando o início de uma thread já expandida, e os botões para exportá-la em Markdown ou PDF, ou gerar um link que permite visitá-la diretamente.
Depois de esticar uma thread, ficam disponíveis 3 botões de ação: copiá-la em formato Markdown (prontinho pra colar no Obsidian), copiar uma URL para acesso direto a essa expansão1 (como este exemplo real), ou exportar o conteúdo como PDF.
Eu uso muito os expansores de threads, porque elas fornecem material de grande qualidade pras minhas referências arquivadas no Obsidian.
Eu tenho demanda frequente de esticar (ou desenrolar/unroll) threads do Fediverso, porque arquivo no Obsidian os meus posts (e threads) que possam servir para referência futura, já que a experiência demonstra que a existência e integridade das threads na web é efêmera, e o interesse em seu conteúdo é de longa vida.
Para o meu uso prático, as 3 opções (markdown, link e PDF) bastariam, mas eu aproveitei que estava com a mão na massa e incluí mais uma funcionalidade: formatar visualmente as threads, para uso em ilustrações e screenshots.
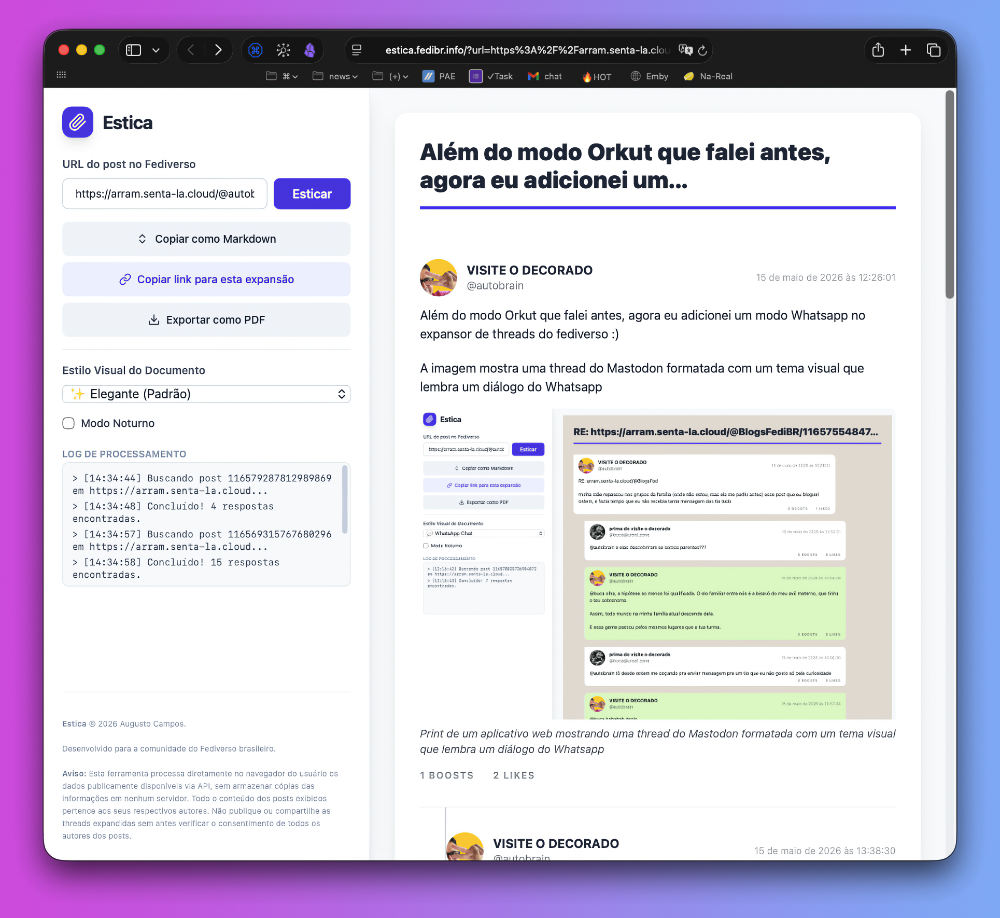
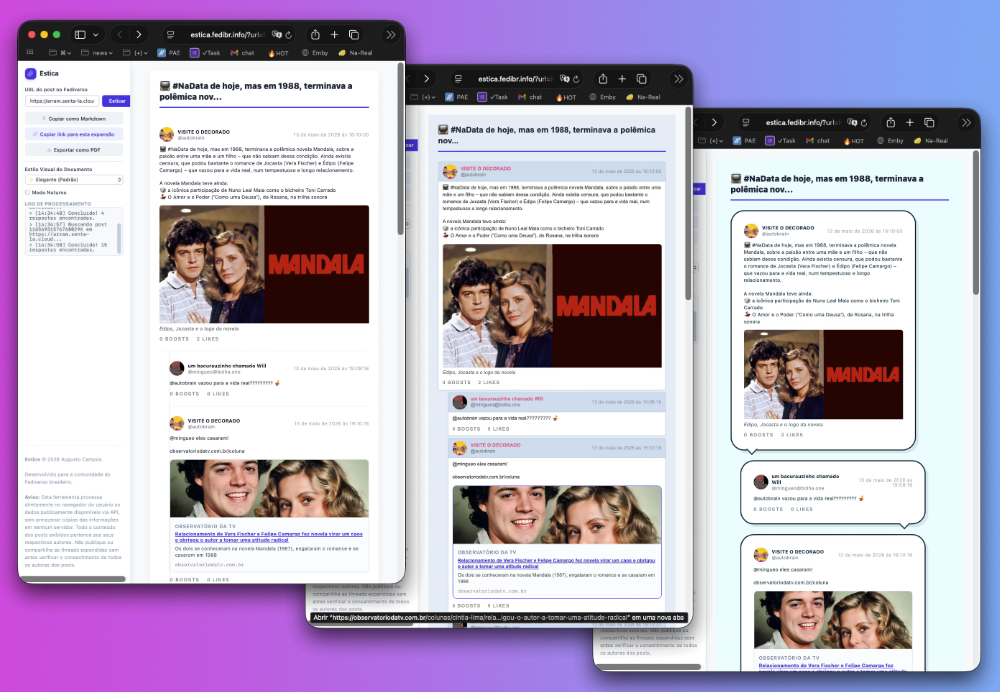
Uma amostra de 3 temas visuais de formatação das threads do Fediverso no Estica: Clássico, Orkut e Quadrinhos
Assim, incluí 22 estilos visuais, que podem ser selecionados à vontade, antes ou depois de fazer a expansão da thread. Tem para todos os gostos: sóbrios, coloridos, de alto contraste, alta legibilidade, retrô, imitando o fórum do orkut, imitando o whatsapp, história em quadrinhos e mais.
Mas por que?
Há mais de um ano eu vinha usando pra isso uma rotina em javascript adaptada, mas os limites dela estavam me incomodando cada vez mais frequentemente, então fiz o que se faz nessas horas: reinventei a roda, agora com suporte aos recursos que me faltavam (especialmente no tratamento de imagens, alt text e cards descrevendo links externos/anexos).
O resultado é o Estica, que eu criei pra meu uso, mas está disponível para quem mais tiver demanda de expandir threads do Fediverso.
Ele usa o modelo que eu não curto, que é webapp javascript com um framework empacotado - mas podia ser bem pior, porque nesse sentido eu usei só o Tailwind, pra facilitar na questão da estilização.
Sobre privacidade e autoria dos posts
O Estica não armazena dados de ninguém, em servidor nenhum. Ele baixa e processa diretamente no navegador do usuário os dados do post ou da thread que você apontar, sempre fazendo uso da API pública do Mastodon em sua versão sem autenticação, para garantir que só terá acesso a conteúdos disponíveis sem qualquer restrição de natureza geral.
Mesmo assim, não custa sublinhar: assim como acontece quando você visualiza os posts em um cliente de uso geral, todo o conteúdo dos posts exibidos continua a pertencer aos seus respectivos autores.
Não cometa a falha que eu já cometi e hoje me arrependo, que é o erro de compartilhar as threads expandidas sem antes verificar o consentimento de todos os autores dos seus posts - seja expresso nos termos de uso que ele adotou, ou consultando-os diretamente.
O Estica está no ar e à disposição dos interessados. Seu código-fonte também está integralmente disponível para consulta no mesmo arquivo HTML da página, para quem quiser conhecer como funciona.
Para preservar a privacidade dos autores dos conteúdos, a expansão não é armazenada, e será regerada a cada acesso à URL. ↩
Um dia o imperador acordou sentindo a ânsia de ter a mais perfeita pintura de um caranguejo. Procurou o mais talentoso e renomado artista de toda a Ásia, e lhe ofereceu riqueza, um palacete, servos, e os melhores materiais artísticos, para que ele pintasse esse quadro.
Anos passaram, e nada de notícias do artista. Até que o imperador cansou de esperar: foi até a casa e, já ao entrar, antes mesmo de ver o pintor, notou que todas as telas espalhadas pela casa estavam em branco.
Tomado pela ira, o imperador concluiu – corretamente – que o pintor não tinha feito esboço nenhum, não havia praticado, passou anos sem colocar em prática a ideia para a qual havia sido escolhido.
Nesse momento, entra na sala o artista. Com profundo respeito, reverencia o imperador e, ato contínuo, pega um pincel ao lado da maior das telas e, com um movimento rápido, desenha nela um caranguejo.
Caranguejos. Katsushika Hokusai, 1808. Nanquim e tinta colorida sobre papel.
Naquele fugaz minuto, o artista havia pintado o caranguejo perfeito, reconheceu imediatamente, o embasbacado imperador.
O artista, expressando sua gratidão pelo longo e generoso patrocínio recebido, retribui com uma explicação que iluminou o imperador, mais do que a perfeição da pintura: ele não tinha como pintar antes, pois precisava que o caranguejo existisse nele primeiro, já que a arte é um ato de “não-ação”, e a perfeição só vem onde há lugar para a naturalidade e espontaneidade.
Pelo esforço construímos produtos, mas o sublime demanda outros caminhos.
(eu não lembro onde eu conheci esse conto zen originalmente, mas sei que foi na década de 1980, porque lembro da primeira vez que eu o usei numa situação prática na vida, e foi ainda na adolescência)
Minha origem familiar é um caldo bem misturado (tive bisavó que nasceu escravizada, bisavó caiçara filha ilegítima de herdeiro suiço, bisavô que nasceu na Alemanha e veio pra cá às vésperas da 1ª Guerra Mundial, bisavô que prestou apoio logístico especializado a quem veio primeiro demarcar as terras onde mais tarde foi fundada Joinville etc.) e a família toda curte a historiografia disso.
Hoje, a pedido da minha irmã do meio, a minha tia compartilhou imagens e uma tradução para o português, feita por ela mesma, das anotações familiares feitas a partir de 1886, com caneta, em letras cursivas semigóticas, nas páginas iniciais de uma bíblia protestante que ela como filha mais velha herdou da geração anterior.
Cabeçalho da primeira página das anotações genealógicas da família, numa bíblia luterana do século 19. Texto em alemão, escrita cursiva, em tinta preta.
É uma árvore genealógica mantida por duas ou 3 gerações de meus familiares, sucessivamente. Conta a história dos nascimentos (e outras efemérides: quem lutou em guerras, quem teve filho fora da nota fiscal etc.) do ramo do meu avô materno, num período de cerca de 70 anos compreendendo séculos XIX e XX, e que começa algumas décadas antes do início das anotações.
Massa demais.
Não são informações novas: esse período deve ter sido tão traumático para eles – que passaram pelos horrores da 1ª Guerra Mundial e uma sequência de migrações (que hoje chamaríamos de fluxo de refugiados) entre regiões que hoje são da Alemanha, Polônia e Romênia antes de virem pras Américas definitivamente em 1924 – que essa memória foi passada pras gerações futuras de várias outras formas também, inclusive com muita riqueza de histórias contadas tomando um café ou um chopp.
Um detalhe interessante é que o meu avô materno deu continuidade a essas anotações, mas aí em um caderno à parte – e esse caderno está aqui em casa, pronto para um dia virar um estudo que quero aprofundar, e que começa no território onde hoje fica a minha cidade natal, Joinville – mas meses antes da chegada oficial dos primeiros europeus para fundar a povoação da colônia.
Uma nota de rodapé, solta, mas interessante: descobrimos hoje que a família da amiga historiadora com quem há mais de ano venho conversando sobre essas minhas intenções, e que com sorte e vento a favor um dia vai ser a minha orientadora nesse projeto, está mencionada nominalmente naqueles registros da bíblia da minha família! E é uma conexão dupla, porque tanto pode ter sido na passagem pela (hoje) Polônia, quanto nas chegadas ao norte de Santa Catarina.
Eu já escrevi antes, e hoje repito: acredito sinceramente que o caso de uso mais generalizado das tecnologias de IA hoje populares (LLM, GPTs, etc.) é a produção de materiais que quem pediu não deveria pedir, quem vai receber não vai valorizar, e quem precisa entregar não deseja elaborar.
Um robô de lata, brinquedo japonês da década de 1940
O custo social e pra sustentabilidade fica AINDA MAIS triste quando se considera isso, afinal pois o ideal seria não pedirem, não ser recebido, e não ser elaborado: uma definição completa de esforço que não gera valor nem contribui para o resultado.
Ou, quando muito, se refere a algo que é feito por questões de maquiar imagem dos envolvidos – como nas expressões "pra inglês ver", "jogar pra torcida", e similares.
Mas é isso.
FAQ:
1. O texto acima é uma defesa do uso de LLM?
R. Não
2. O texto acima indica que esse é o único caso de uso de LLM?
R. Não
3. O texto acima indica que esse é o principal caso de uso de LLM?
R. Não
Axe é o meu CMS estático open source, especializado em blogs, que dispensa bancos de dados e recursos na nuvem, e mantém sites que carregam bem até em planos baratos de provedores brasileiros.
Eu criei o Axe em 2012, logo depois de perder definitivamente a paciência com a complexidade crescente do WordPress (após já ter passado pelo mesmo ciclo com o Drupal, 5 anos antes).
O Axe – que publicou este post que você está lendo – é um sistema gerenciador de conteúdo, em PHP modo shell que, a partir de arquivos contendo apenas o título e o corpo do post, em formato texto ou HTML, gera e atualiza toda a estrutura típica de um blog: índices, páginas de posts individuais, feed, tags, sitemap, etc.
Além de ser simples1 na operação, o Axe é da família dos CMS estáticos, o que significa que ele só processa os posts no momento das inclusões e alterações – na hora de servir a página, ele dispensa ter PHP, Javascript2, nuvem etc., porque a página é gerada como um HTML estático.
Eu uso o Axe literalmente todos os dias, portanto não foi desuso a causa desse tempo todo sem atualização: a questão é que esse CMS foi desenvolvido a partir de um mapeamento das minhas demandas pessoais de publicação de blogs, e já em 2013 ele ficou completo em termos de recursos.
Assim, a partir de 2013, com o Axe já rodando em todos os meus blogs e mais alguns sites, as únicas alterações que eu fiz na base de código dele foram pra manter a compatibilidade com as mudanças de sintaxe do PHP em modo shell (entre o PHP 5 e o PHP 8, basicamente) – que nem foram muitas.
O inesperado (considerando o tempo que faz desde a última vez que isso aconteceu) contato de um usuário interessado em usar o Axe me fez perceber que a versão disponível para download ainda era compatível com o PHP 5, e daria erro em provedores modernos. A solução foi simples: portar para a versão pública os ajustes que fiz nesse período (meia dúzia de linhas, se tanto), e gerar um novo pacote.
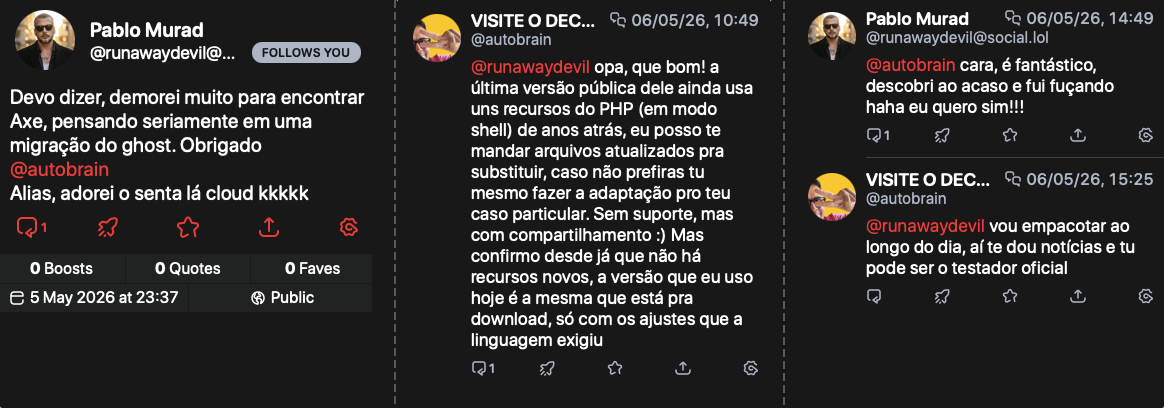
A conversa com o Pablo, que motivou a atualização do Axe em 2026
Literalmente, demorei mais tempo escrevendo e publicando o post de anúncio da atualização do que atualizando o pacote – que o próprio usuário solicitante validou para mim, em uma instalação bem-sucedida, logo depois.
Aproveitei o mesmo embalo para colocar no ar uma página centralizando o download e a documentação do Axe, para que futuros novos interessados possam fazer as coisas na ordem que preferirem, sem precisar olhar todo o histórico de publicações.
Vale destacar: as atividades de operação do Axe ocorrem via linha de comando, no Terminal, portanto ele exige que você tenha acesso shell (SSH ou similar) ao seu servidor de hospedagem e saiba usá-lo.
O Axe também exige que o PHP esteja disponível na linha de comando, embora dispense a ativação do mod_php no servidor web, já que o interpretador PHP é usado apenas em modo shell, no momento da publicação ou gestão do conteúdo – e não para servir as páginas.
Tchau, Github
Também aproveitei o mesmo embalo e descontinuei o repositório do Axe no Github. O Github em 2026 não é mais o que era em 2013 (para dizer o mínimo), e o meu interesse em desenvolvimento colaborativo do Axe é baixo ou inexistente, pois eu o considero completo.
O código continua aberto (licença Apache 2.0) e disponível para quem quiser conhecer e experimentar.
Que, neste caso, não é sinônimo de fácil, embora o Axe nem seja dos mais difíceis também. ↩
A não ser que você inclua essa demanda na sua própria personalização, layout etc. ↩
Sensor conectado mede continuamente a temperatura e umidade, é fácil de conectar à Alexa, e funciona 9 meses com um par de pilhas AAA.
Meu caso de uso pra termômetros dentro de casa é bem específico e prático: uma das características do meu autismo é não ter a reação de me agasalhar ao sentir frio, então sou capaz de passar horas seguidas em desconforto por não notar que é hora de colocar um casaquinho ou pegar mais um cobertor.
Desde 2025, o arsenal de termômetros da minha casa (que já tinha vários modelos analógicos e digitais) ganhou dois complementos conectados à Internet, na forma de sensores de temperatura Tuya1, integráveis à Alexa e outras arquiteturas de automação.
Um par de sensores de temperatura e umidade com suporte a WiFi
Eu coloquei um no escritório e o outro no quarto, e o uso que eu faço deles é o mais básico possível: poder perguntar “Alexa, qual é a temperatura na escrivaninha?” (ou na cabeceira), e receber instantaneamente a resposta audível, sem tirar os olhos do que estou fazendo.
Vale sublinhar que a Alexa e similares sabem responder temperaturas sem o sensor, mas aí informam a temperatura externa da região2 – que aqui no meu caso, especialmente no outono e inverno, tende a estar pelo menos uns 10 graus abaixo da temperatura interna, e é um dado que não resolve a minha demanda específica.
Esses sensores também incluem o recurso de medição de umidade, e podem ser usados na configuração de ações automatizadas – por exemplo, ligar um climatizador, ou enviar uma mensagem a alguém, quando a temperatura ou umidade do ambiente atingirem determinados níveis. Não é algo que eu tenha demanda, e se eu fosse fazer algo assim, priorizaria evitar os riscos associados.
Para mim, entretanto, o uso no modo mais básico já é suficiente para o objetivo de não mais acordar de madrugada tremendo de frio, nem passar o dia desconfortável por não perceber que deveria colocar uma blusa de manga comprida.
Ciclo de carga da bateria: 9 meses
Cada um dos sensores funciona com duas pilhas AAA. Eu os ativei3 em agosto de 2025, com pilhas Duracell, e na manhã de hoje, pela primeira vez, um deles começou a piscar seu led (que normalmente fica apagado), avisando que estava quase sem energia.
Era o fim da vida útil do primeiro par de pilhas – troquei por um par novo, e tudo normalizou. Já criei um lembrete no Todoist para a cada 8 meses trocar de novo, e assim reduzir o risco de alguma pilha vazar dentro do aparelho.
Esse link é ilustrativo – eu comprei no AliExpress, mas em outro link, que não está mais no ar. ↩
Exceto alguns modelos bem específicos que incluem sensor de temperatura local, que geralmente são mais caros e anunciam em destaque essa característica. ↩
Usando os apps da Tuya e da Amazon, e seguindo as instruções que os acompanharam. ↩
É subnicho de um subnicho, eu sei… mas quem aderiu aos tecladinhos TH40 vai gostar de saber que existe um estojo que o abriga perfeitamente.
O TH40 é um teclado praticamente mágico para levar na mochila, porque ele é bem menor que os usuais, mas tem teclas de tamanho normal, super confortáveis de digitar.
Para fazer caber, ele remove as duas fileiras superiores (teclas de função e números), cujos símbolos passam a precisar ser acionados por meio de combos da tecla Fn, estrategicamente posicionada entre as duas metades da barra de espaços convenientemente bipartida.
Eu já contei os detalhes sobre ele em um post anterior aqui no blog, mas hoje tenho um complemento interessante: embora jamais tenha encontrado um estojo feito especialmente pra ele, descobri que os estojos feitos para o multímetro Fluke T5-1000/T5-600 tem o tamanho exato pra abrigá-lo, e ainda sobra espaço pra umas canetas e acessórios.
A foto abaixo é do meu teclado, no meu estojo, de agora:
Teclado TH40 acondicionado em um estojo feito para um multímetro Fluke T5-1000.
Comprei o estojo no Ali Express, chegou em menos de 10 dias, e há algumas semanas já está em uso contínuo pra abrigar o teclado, que eu comprei em 2025 e também está em uso contínuo desde então1.
Observação importante: aquele estojinho de canetas e material de anotações não faz parte, mas cabe perfeitamente no bolso telado pra acessórios, então é um bom bônus. Ele é de nylon, tem 3 compartimentos pra canetas, dois bolsos abertos e um com zíper, e eu comprei no AliExpress também.
Mais de uma função em cada teclinha: como funciona?
O TH40 é mapeável, ou seja, o usuário configura (num aplicativo via web) quais símbolos ele quer ter em cada tecla e em cada combo.
Eu uso um mapa de teclado que já aproveitei em outros teclados com layout compacto antes, e com o qual já estou acostumado e, pra facilitar, desenhei e mandei imprimir na Yuzu Keycaps um conjunto de teclinhas personalizadas que indicam qual a função secundária de cada tecla, como você pode ver no detalhe:
Teclado TH40 no estojo, visto de perto - note que várias teclas têm símbolos secundários impressos nelas.
Escolher a função secundária de cada tecla não tem regra, mas eu defini um padrão pessoal que adoto sempre: os números ficam na fileira de cima, os acentos no canto inferior esquerdo, pontuação e lógica ficam no canto inferior direito, e a fileira do meio fica reservada aos utilitários e complementos.
Foto do conjunto de teclinhas que eu desenhei no site da Yuzu Keycaps, que imprimiu e me enviou, do outro lado do mundo
E há também os combos terciários, com uma tecla modificadora adicional além da Fn, que eu uso para, por exemplo, acessar as funções multimídia e as teclas F1 a F12, que uso bem mais raramente.
Para ilustrar, esse é o mapa das funções secundárias das minhas teclas, gerado no utilitário on-line de configuração:
Print de uma tela do utilitário de configuração, mostrando os combos secundários definidos para o meu TH40.
Note que dei um jeito de encaixar comandos do próprio teclado (conexões bluetooth, iluminação das teclas, consulta de nível da bateria) e ainda sobrou espaço para repetir em lugares bem convenientes alguns símbolos que na rua eu uso com mais frequência, como arroba e hashtag.
Para saber mais
Eu gosto tanto do TH40, que já escrevi sobre ele várias vezes, e hoje certamente não será a última. Vamos aos links:
Os links para lojas e produtos, que constam neste post, são apenas informativos, e não incluem códigos de afiliado ou similares.
Mas só fora do escritório, porque eu gosto dele pra textos, que eu digito pelas reuniões da vida, mas não pra programação e planilhas, que precisam de muito mais números e símbolos, e são parte da minha rotina no escritório. ↩